Uplift models用于预测一个treatment的增量反馈价值。举个例子来说,假如我们想知道对一个用户展现一个广告的价值,通常的模型只能告诉我们用户在展示广告后的购买意愿很强,但事实很有可能是他们在被展示广告之前就已经很想购买了。Uplift models聚焦于用户被展示广告后购买意愿的增量
1 背景和问题定义
Uplift models预测增量值,也就是lift的部分:

而传统模型通常直接预测目标:

这里我们用用户买不买来举个例子(但这里的目标可以根据具体场景改变)。个体在面对treated或者untreated之后的反应可以分为下面四种:
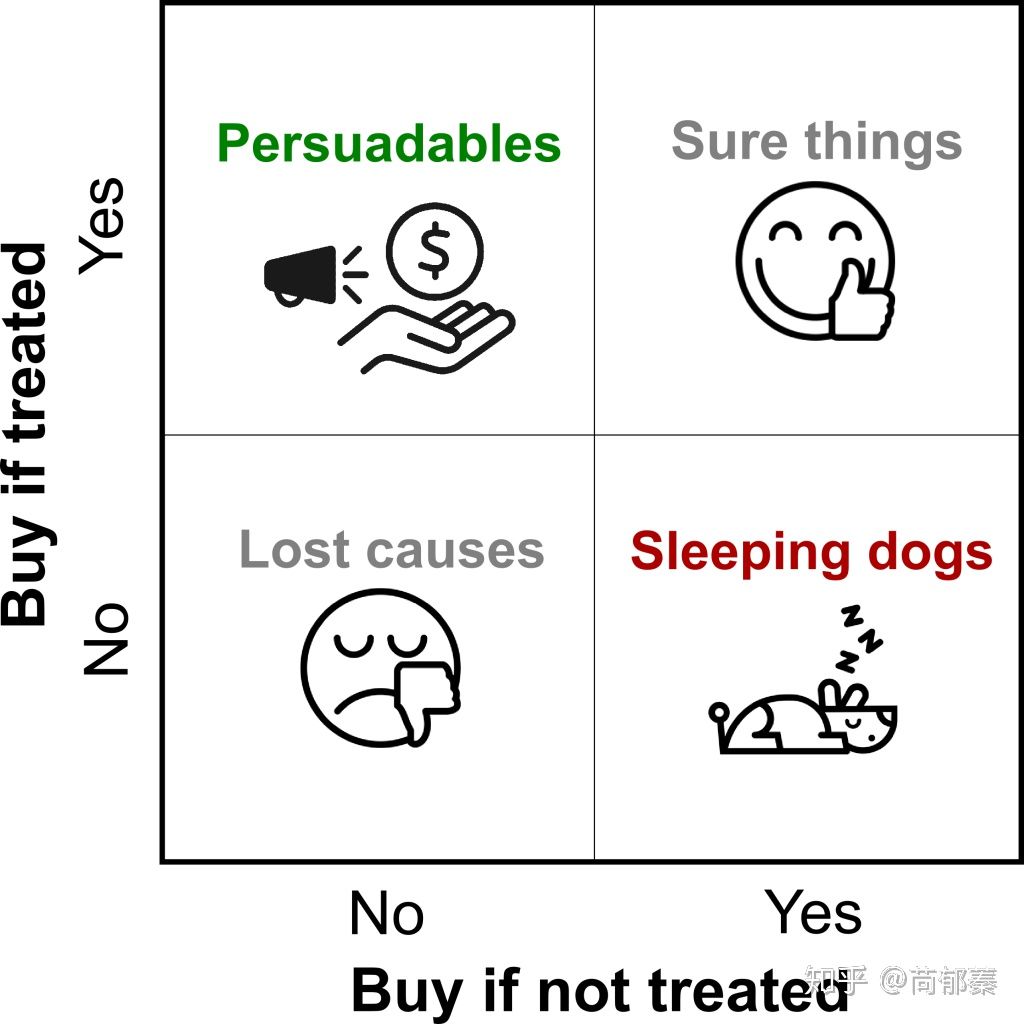
在一个理想的世界中我们能够将每一个个体根据类型划分,然后找到“persuadables”的那一波人,也就是投资汇报率最高的那一波人。对于“sleeping dogs”的那一波人肯定不是营销的目标人群。但是在现实生活中我们却没有办法准确的判断一个人是属于哪种类型,因为我们不可能对同一个用户treated或者notreated。但是借助统计和机器学习的知识,我们就可以得到相似的用户大致会怎么反应。这就是uplift模型的核心,每一个用户会得到一个位于-1到1的lift score,用于指导用户人群的选择。 因此整个问题可以表述为:
2 方法
2.1 two model
分别对实验组和对照组建模,然后求差值。
2.2 The transformed outcome tree
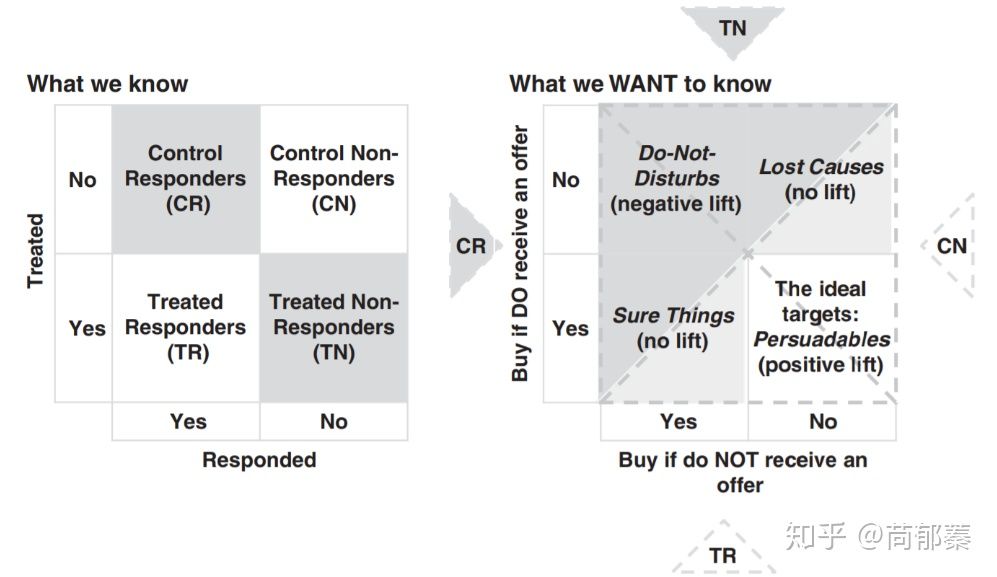
Uplift models需要每一个人的两方面信息:是否给予treatment,产出label。理想情况下,我们可以得到一些个体在随机分配到实验组(treat group)和对照组(control group)后的数据,基于他们对于treatment的反应,outcome label可以被转化为下面这个矩阵(Athey and Imbens 2016)(实际情况中可以有其他的正负样本划分方法):
可能在第一眼的时候觉得这个目标矩阵不太靠谱,像拍脑袋的结果,为啥没有买的给不给treatment都是0?为什么给了treatment买了就是2?看起来非常不直观,但是是有道理在里面的,假如将一群人随机分为控制组和对照组,最后得到的平均值矩阵就是这群人的lift。 为了说明这个问题,考虑有一群人,人数为2n,其中n个给了treatment t,另外n个不给作为对照组。为了简单起见我们将i =1 ,…, n为treatment组,i =n+1 ,…, 2n为控制对照组。对于每一个用户,原始的outcomes和转换后的分别为 和 ,那么对于这群人,对于购买行为的lift为:
也就是说,转化后的outcome取决于前一个group的lift,这个优雅的转换大大简化了lift问题,我们可以直接对z建立回归模型,我们就可以得到对于基于特征x表征的用户的uplift:
3 Evaluation metrics
uplift建模过程中最难的是提出一个有效的评估指标,我们下面讨论了一种评估指标,然后介绍如何将这个指标引入Transformed Outcome method。 最典型的评估指标是Qini curve,
nt,1(φ)和nc,1(φ)分别代表着对照组和控制组中outcome为1的人数,分数φ表示观察人群占目标人群的比值,Nt 和 Nc表示实验组和对照组的总人数(独立于φ),因为Nt 和 Nc其实并不独立于φ,也就是实验组和对照组的均衡不是随机的,而是φ的一个函数,所以Qini curve会自然的膨胀。 为了纠正这一点,引入了以下两版曲线:
其中nt(φ) 和nc(φ) 分别代表了实验组和对照组中观察人群的比例。 首先,我们实现了传统的cumulative gain chart (Gutierrez and Gerardy 2016)。其中φ近似为:
这是对uplift的无偏估计。 我们同时也包含了adjusted Qini curve,其中φ 为:
实例 这里采用一个uplift库pylift做例子,文档见扩展资料。 模型创建 简单的模型创建如下,使用xgboost作为基础模型: from pylift import TransformedOutcome up = TransformedOutcome(df, col_treatment=’Treatment’, col_outcome=’Converted’) up.randomized_search(n_iter=200) up.fit(** up.rand_search_.best_params_) up.plot(plot_type=’cgains’, show_practical_max=True, show_no_dogs=True)
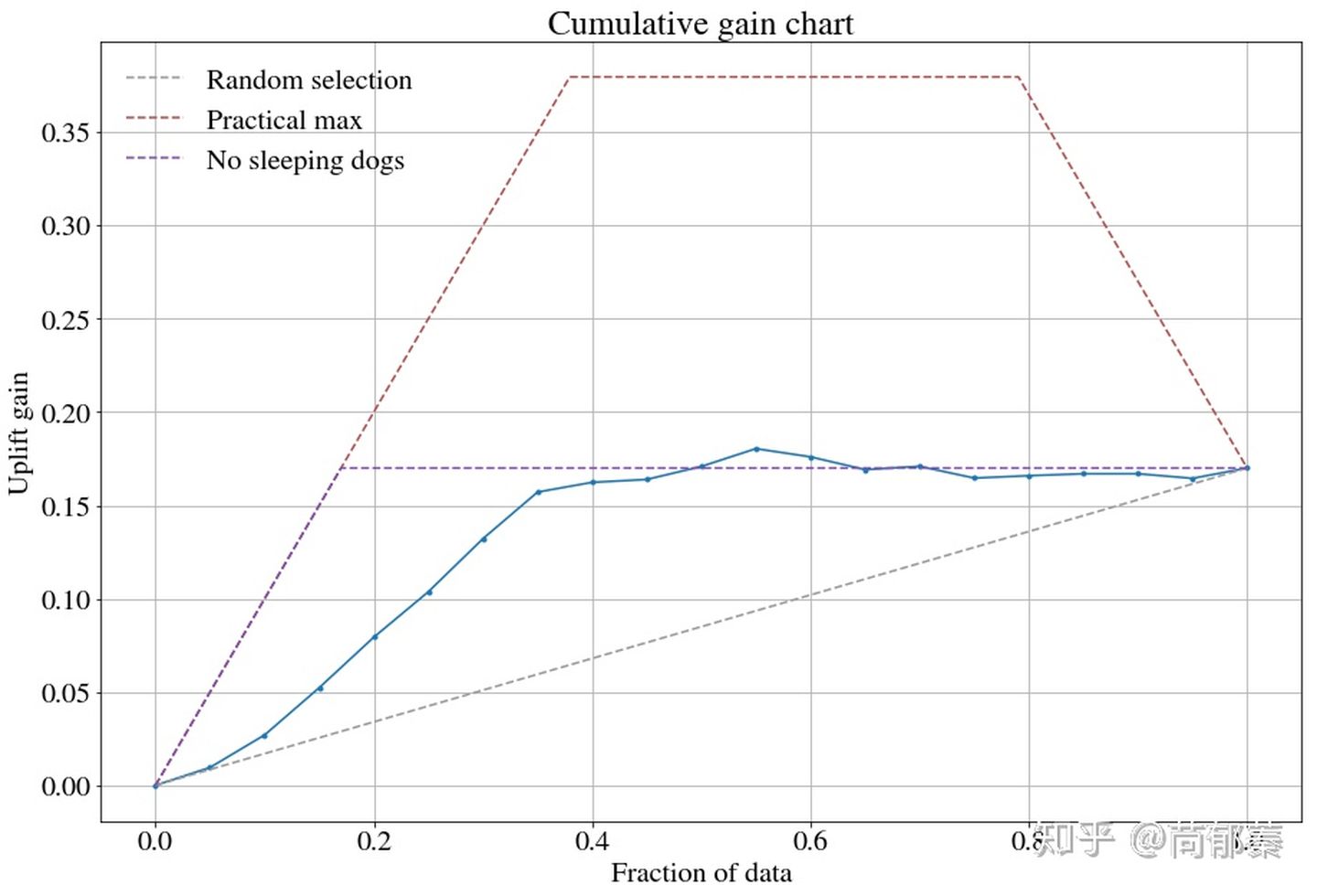
Model 评估
假如你需要自己做模型评估,就需要三个向量:
- Treatment: 0, 1 list,用来表征实例在控制组还是对照组;
- Outcome: outcome — 可以是0, 1 list或者连续值.
- Predictions: 预测得到的uplift值,用来对customers针对Qini curve的x轴进行排序 . 调用方式如下: from pylift import UpliftEval upev = UpliftEval(treatment, outcome, predictions, n_bins=20) upev.plot()
注 1.[3]证明了最小化模型的uplift和z的MSE 等价于最小化模型的uplift和真实的uplift。
参考文献和扩展资料: https://humboldt-wi.github.io/blog/research/theses/uplift_modeling_blogpost/ R包 https://cran.r-project.org/web/packages/uplift/index.html python包pylift https://tech.wayfair.com/data-science/2018/10/pylift-a-fast-python-package-for-uplift-modeling/ Cumulative_Gain_Chart曲线 http://mlwiki.org/index.php/Cumulative_Gain_Chart [1] Gutierrez, P., & Gérardy, J. Y. (2017, July). Causal Inference and Uplift Modelling: A Review of the Literature. In International Conference on Predictive Applications and APIs (pp. 1-13). [2] Athey, S., & Imbens, G. W. (2015). Machine learning methods for estimating heterogeneous causal effects. stat, 1050(5). [3] Hitsch, G., & Misra, S. (2018, January). Heterogeneous Treatment Effects and Optimal Targeting Policy Evaluation. Preprint